My Experience in the National Tuberculosis Center
Background:
Recently, we got a chance to work for the National Tuberculosis Center, Bhaktapur - a center for tuberculosis treatment, prevention and cure. As a software engineer, people may think about what will I do in a tuberculosis center? But wait! Now, Things are growing so rapidly, we all need interdisciplinary actions for every event. Let it be we trying to generate a graph for a National Stock Exchange, We need help from statisticians or a health professional may need a tool for data management where we can play our role. So, my involvement in the NTB(National Tuberculosis Center) was for data management.
NTB uses a device named GeneXpert.The device which helps for the test of tuberculosis bacteria/ resistance to a drug Rifampicin. A sample of sputum is tested in the device and a result is obtained which doctor use for the diagnosis of TB. Interestingly, the device, after giving a hostname, could send the patient's data to a server. The data sent by the Genexpert machine uses the HL7 protocol.
Health Level Seven or HL7 refers to a set of international standards for the transfer of clinical and administrative data between software applications used by various healthcare providers. These standards define how information is packaged and communicated from one party to another, setting the language, structure and data types required for seamless integration between systems. The information includes the patient information, patient results, machine data that are needed for us to visualize the data into something meaningful.
Here are some samples of hl7 message:
MSH|^~\&||.|||199908180016||ADT^A04|ADT.1.1698593|P|2.7
PID|1||000395122||LEVERKUHN^ADRIAN^C||19880517180606|M|||6 66TH AVE NE^^WEIMAR^DL^98052||(157)983-3296|||S||12354768|87654321
NK1|1|TALLIS^THOMAS^C|GRANDFATHER|12914 SPEM ST^^ALIUM^IN^98052|(157)883-6176
NK1|2|WEBERN^ANTON|SON|12 STRASSE MUSIK^^VIENNA^AUS^11212|(123)456-7890
IN1|1|PRE2||LIFE PRUDENT BUYER|PO BOX 23523^WELLINGTON^ON^98111|||19601||||||||THOMAS^JAMES^M|F|||||||||||||||||||ZKA535529776The above message is divided into four segments: MSH, PID, NK1, and IN1.
A segment contains fields which is separated by the | field separator. Fields can be further separated by ‘^’, the so-called component separator, and contain sub-components denoted by ‘&’ symbol.
MSH (Message Header) contains purpose of the message, e.g. its ID, seeding application, sending facility, receiving an application, receiving facility, type, date and time of the message, its HL7 version, etc.
PID (Patient Identification) holds information about the patient e.g. their ID, name, DOB, address, gender, race, admission date and time etc.
NK1 (Next of Kin) contains details of the person's closet relative/friend.
IN1 (Insurance 1) has details about the health insurance the patient has like Medicare, Medicaid, Tricare, etc. It contains the insurance plan ID, the name of the insurance company, the company's address, the name of the insured person, policy number, etc...
(https://stackoverflow.com/a/46302926/5393816)
Action Plan:
So, we set up a Linux container that could accept the hl7 data and store it in our database. we used the python-hl7 module to parse the data from the machine. So, our initial architecture looked like these:
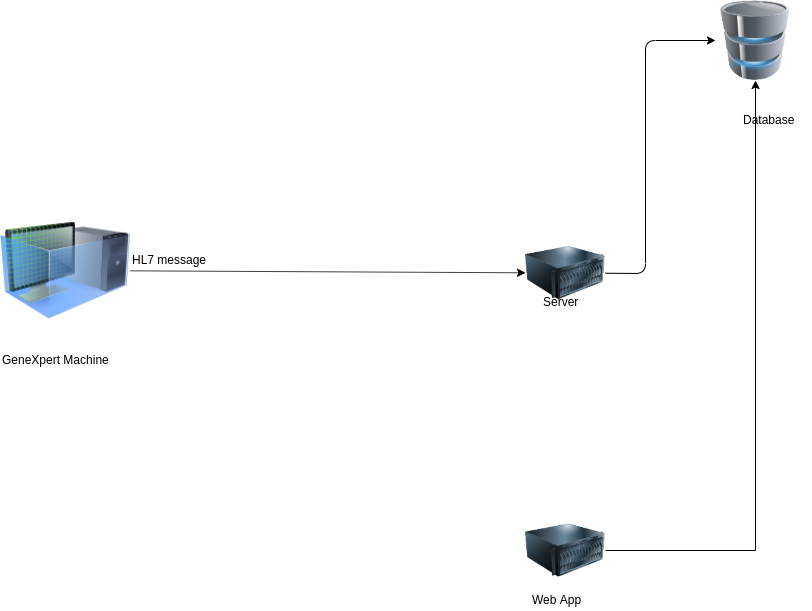
The work was almost completed until the request on the server was too much for our server to handle. The server was unable to handle the requests. We initially assumed that the Genexpert Machine would send 10-20 requests per day. After testing for a day, 40,0000 rows were filled in a day making our assumption wrong. Imagine, the huge request that the server handled that day.
There are nearly 100 Genexpert Devices across the country from which we should be able to retrieve data. Each device sends at most 100s of data a day to a server. In a case where the internet may not run for a few days, the count of data may reach 1000s a day. So, on a worst-case, Let's say all the device has internet failure for a few days, the count will reach thousands and thousands of request from each server. A single server on handling all these requests will easily crash or ignore most of the requests. So, we need a way of handling all the requests. We knew a load balancer was the answer but, the real question was what/how should we do this?
In a few research, we found the answer, HaProxy(http://www.haproxy.org/). HAProxy stands for High Availability Proxy which is a TCP/HTTP load balancer and proxy server. We have written a blog on how to do we set up the load balancer. Here is the link:https://shrestharohit.com.np/using-ha-proxy-load-balancer.
So, 6 virtual Linux container(server) with a load balancer on the top of it was installed. After using the load balancer, these sever were able to handle all the requests efficiently. The architecture of this connection looks like these.
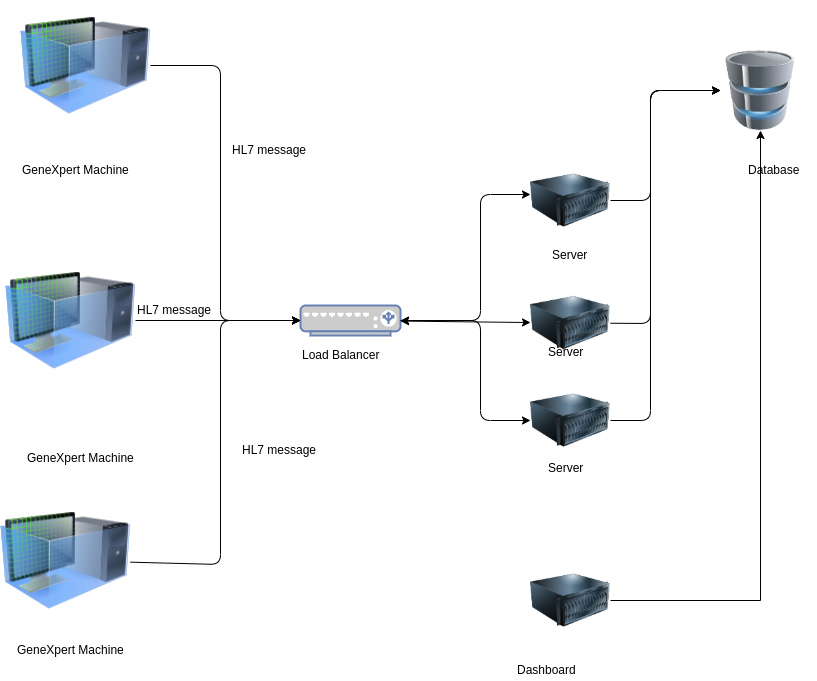
Basically, a load balancer with a round-robin algorithm would distribute the request to different servers. The server handles the request and saves the data to the database. Now, the final process was to show all the data into meaningful information. Since we had all the things we needed Patient info, machine info and patient result
We could see a lot of possibilities. To list a few of them like listing the active devices across the country,the list of machines failing to send response/ is not working for few days, save patient information for future uses, get exact information on certain parameters like total no of patients with RIF resistance detected across the country.
Some of the works we did with the data are :
- List all the machine operating in across the country with their status(delay to send reports to the server
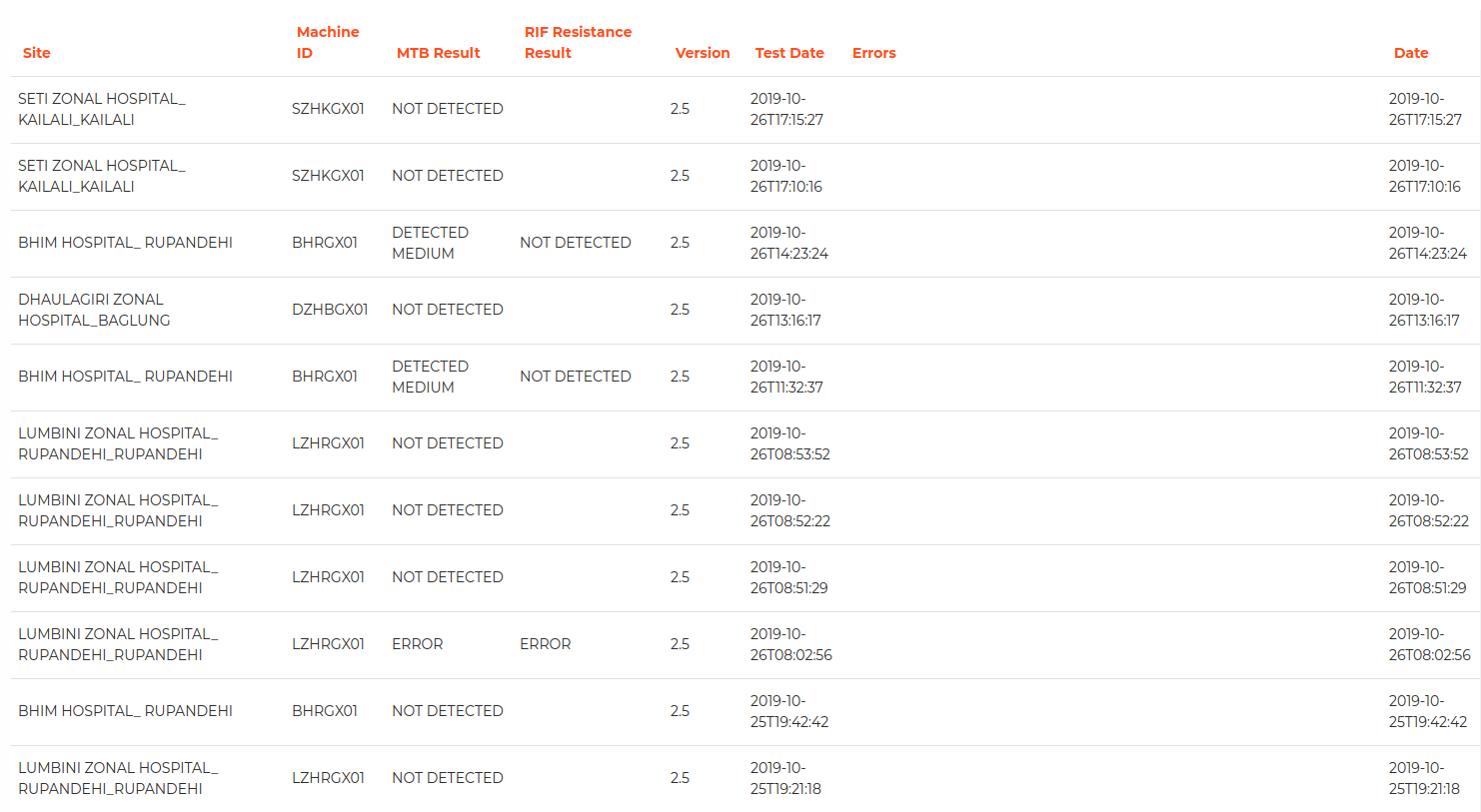
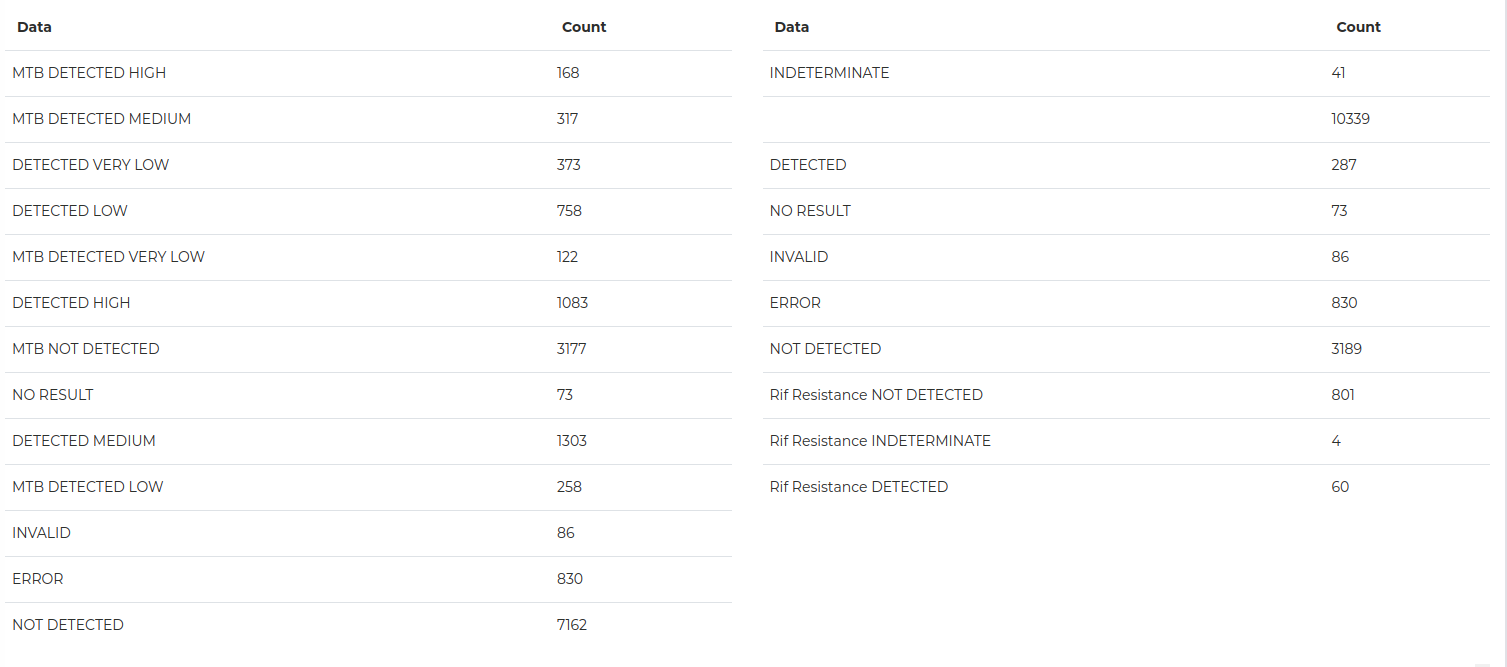
2. Get an aggregate report for the purpose of analysis
3. List machines with delayed data
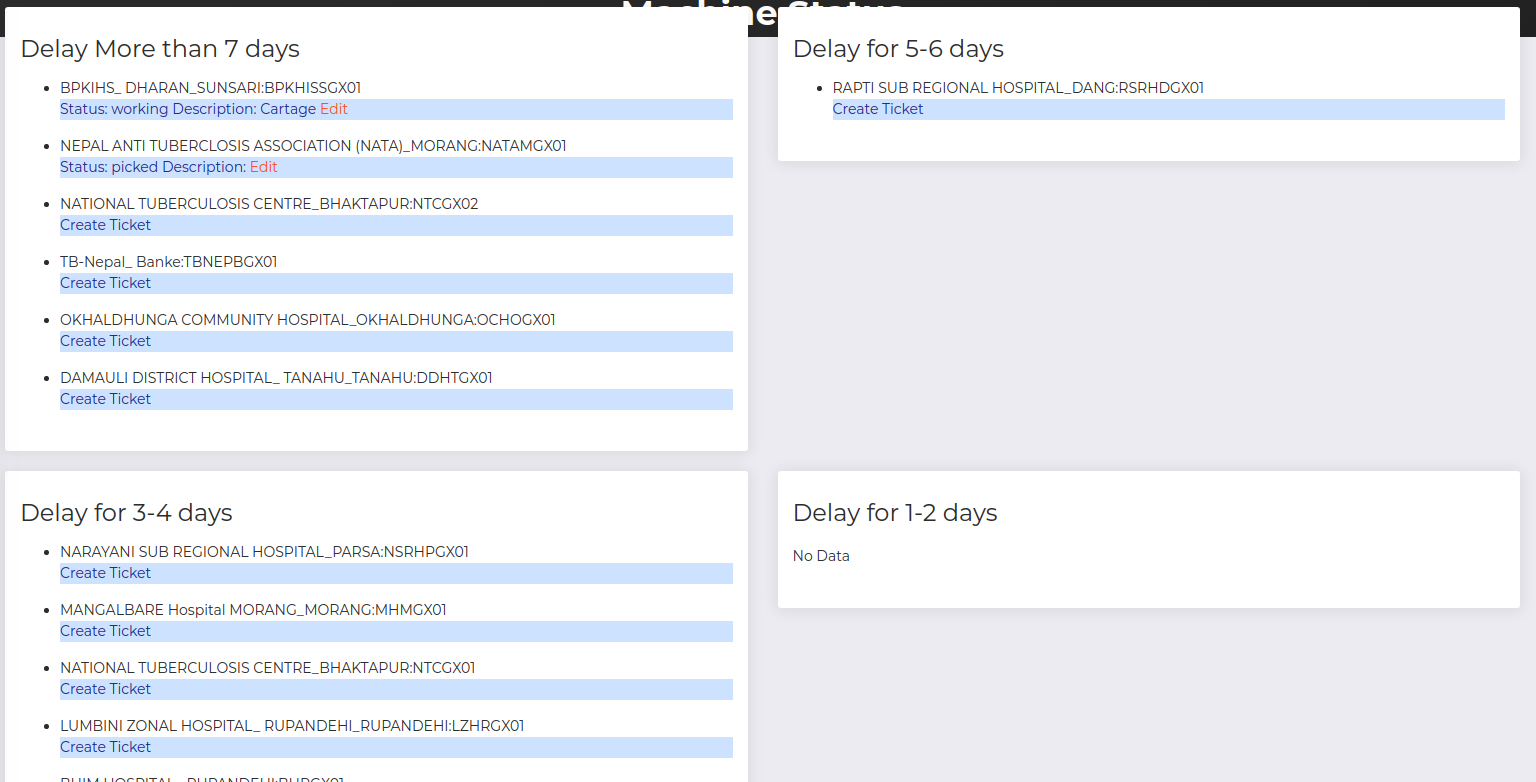
Conclusion:
Being involved in the health sector for a long time, We could see a lot of possibilities for the use of data in our country. Today’s world works on the power of data. Data are powerful in the sense that they help us moving forward with proper judgment.
The chance to work with NTB for exploring the use of health-related data was very exciting and challenging in itself. It seemed very challenging at first, but on working close with the teams,We were able to explore how data could be used for decision making and monitoring various factors across the country.
Team Members:
- Aatish Neupane (https://librenepal.com/)
- Rohit Shrestha